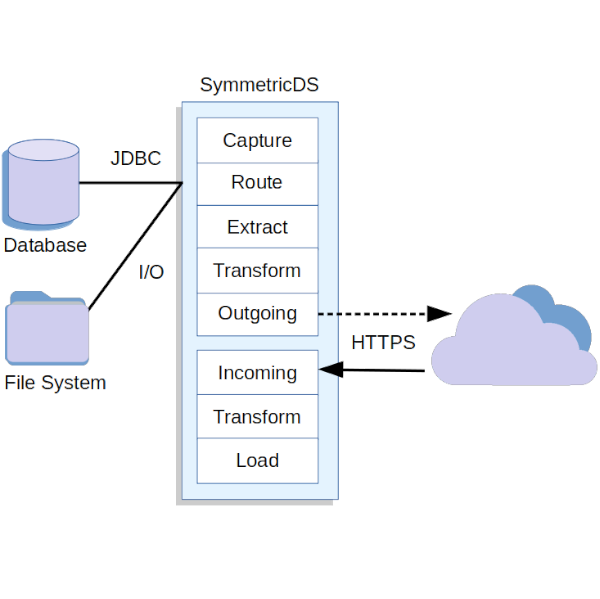
Architecture
Change data capture for tables uses database trigger that fire and record changes into an event table. SymmetricDS Pro includes additional capture methods, including log mining, change tracking, and logical streams. For file sync, a similar mechanism is used, except changes to the metadata about files are captured. The changes are recorded as insert, update, and delete event types. Triggers are installed and maintained on tables based on the configuration provided by the user, and schema changes are automatically detected and adjusted.
Routers run across new changes to determine which target databases will receive them. The user configures which routers to use and what criteria is used to match data, creating subsets of rows if required. Transformations operate on the change data either during the extract phase at the source or the load phase at the target.
 Amazon Redshift
Amazon Redshift Amazon S3
Amazon S3 Apache Kafka
Apache Kafka DB2
DB2 Elasticsearch
Elasticsearch Google BigQuery
Google BigQuery MariaDB
MariaDB MongoDB
MongoDB MySQL
MySQL Oracle
Oracle PostgreSQL
PostgreSQL Snowflake
Snowflake SQL Server
SQL Server SQLite
SQLite Sybase ASE
Sybase ASE